Towards Online Multimodal Social Interaction Understanding
Abstract
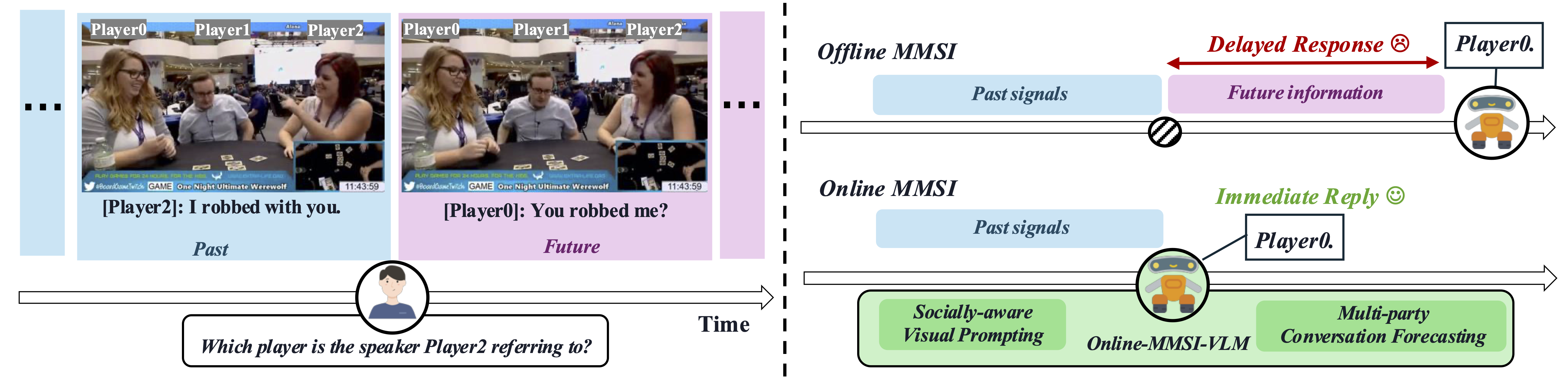
In this paper, we introduce a new problem, Online-MMSI, where the model must perform multimodal social interaction understanding (MMSI) using only historical information. Given a recorded video and a multi-party dialogue, the AI assistant is required to immediately identify the speaker’s referent, which is critical for real-world human-AI interaction. Without access to future conversational context, both humans and models experience substantial performance degradation when moving from offline to online settings. To tackle the challenges, we propose Online-MMSI-VLM, a novel framework based on multimodal large language models. The core innovations of our approach lie in two components: (1) multi-party conversation forecasting, which predicts upcoming speaker turns and utterances in a coarse-to-fine manner; and (2) socially-aware visual prompting, which highlights salient social cues in each video frame using bounding boxes and body keypoints. Our model achieves state-of-the-art results on three tasks across two datasets, significantly outperforming the baseline and demonstrating the effectiveness of Online-MMSI-VLM.




BibTeX
@article{li2025towards,
title={Towards online multi-modal social interaction understanding},
author={Li, Xinpeng and Deng, Shijian and Lai, Bolin and Pian, Weiguo and Rehg, James M and Tian, Yapeng},
journal={Transactions on Machine Learning Research (TMLR)},
year={2026},
}